Mybatis插件实战-京东慢SQL组件
sql-analysis 介绍
GitHub: https://github.com/jd-opensource/sql-analysis
京东开源组件:sql-analysis,它为了解决大促等场景,为了提高日常系统稳定性,和存在的隐患,通过对慢sql的预防和排查,然后基于Mybatis插件体系设计le的一款慢sql分析组件,区别于主流的基于响应时间作为决定因素的慢sql日志分析和预警,它采用了实时根据Explain分析结果+规则引擎的方式进行分析。

一、流程源码设计分析
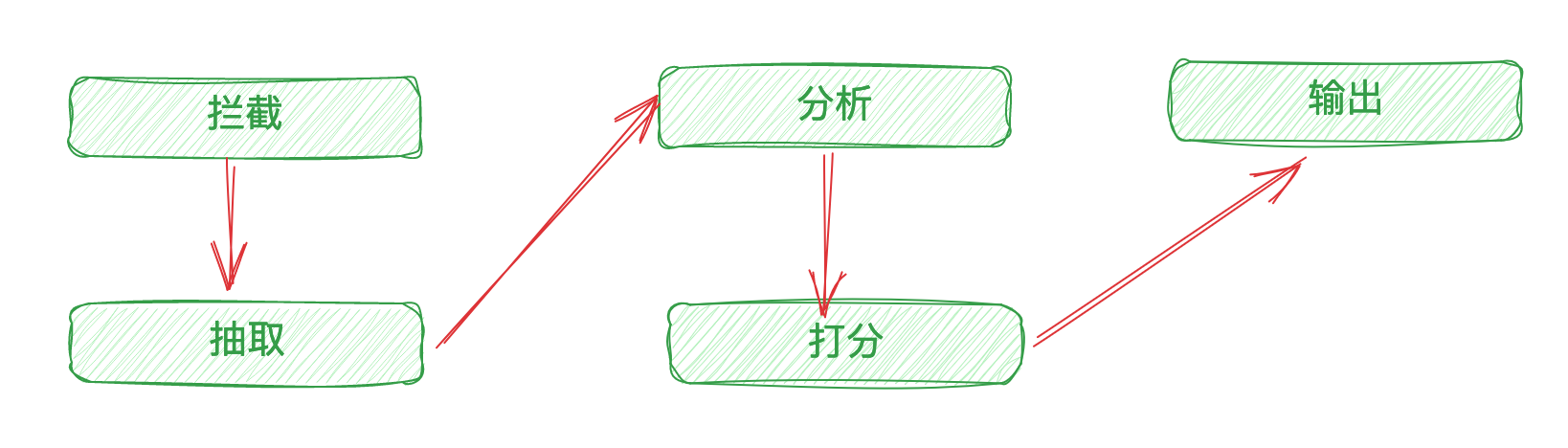
sql-analysis组件的基本原理:
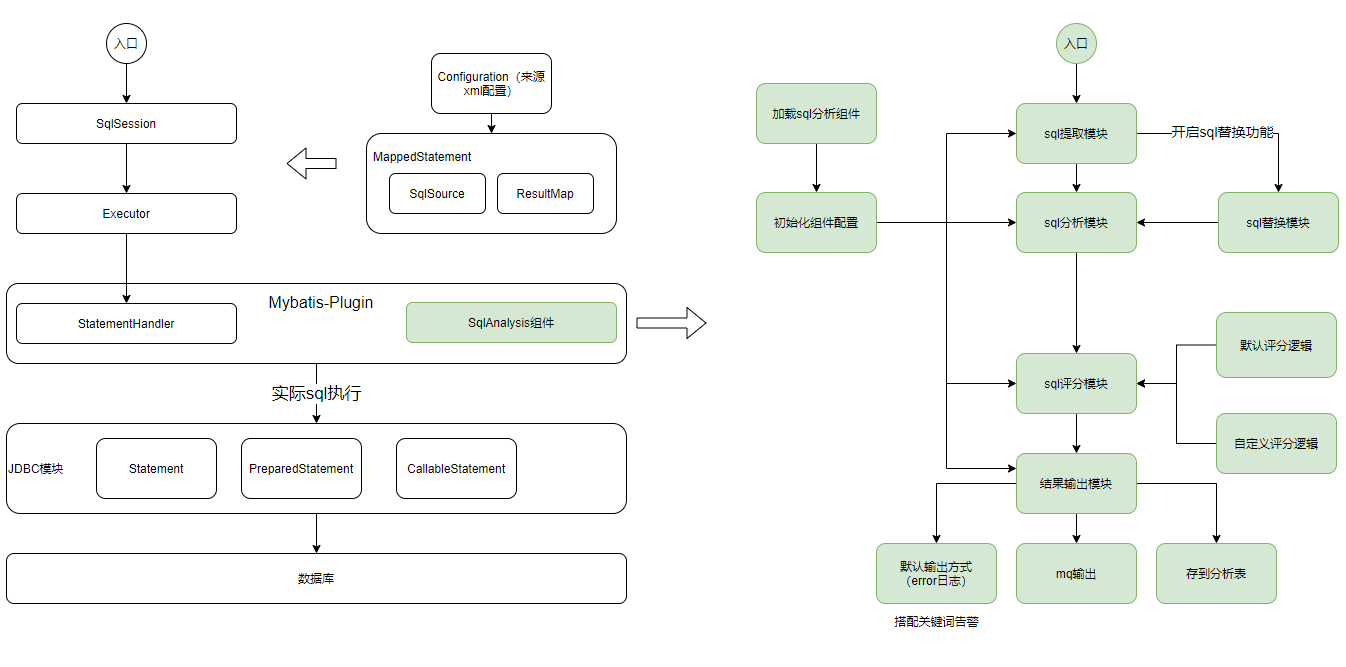
本文基于这个原理,开始分析这个组件的核心的源码,这个组件本身并不复杂,我们需要关注:
它是如何串联起来整合业务流程的?
它里面的关键的几个节点都完成的工作是什么?
二、正文开始
2.1、sql-analysis的源码结构
在上一篇文章中,我们通过在IDEA中导入了sql-analysis组件的源码,然后使用示例工程运行了基本的例子,接下来我们看下源码模块的基本结构:
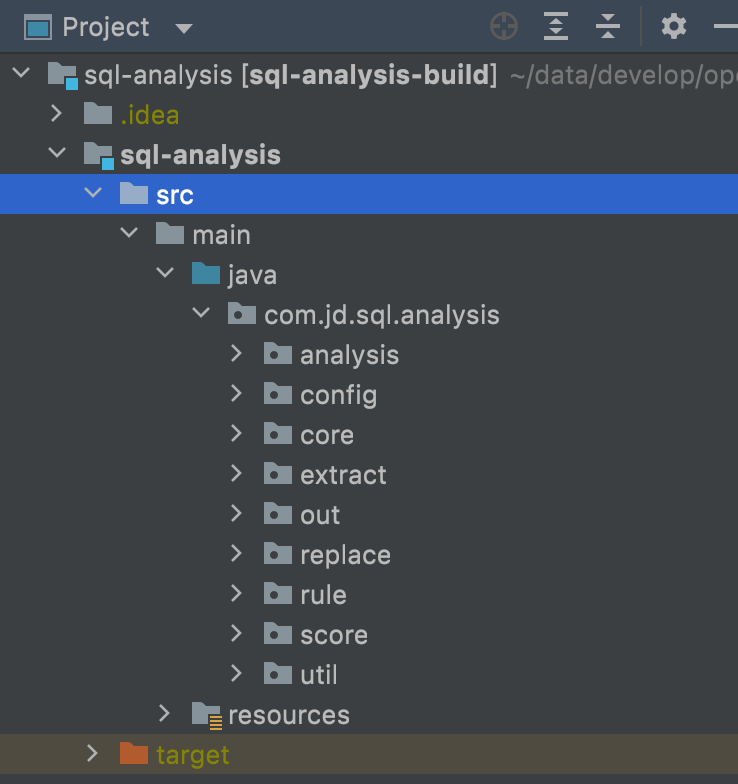
这几个模块的含义如下:
主要分为8个功能模块
2.2、sql-analysis的入口拦截器
从原理图中,我们知道这个组件的核心入口就是自定义了一个mybatis拦截器,这个拦截器所在的模块是模块一core下面,类名称为:SqlAnalysisAspect。整个源码不到162行,我们先来快速看一下,首先类的上面定义了基本的拦截器的配置:

这个是一个非常典型的mybatis的拦截器的配置,然后该拦截器初始化的时候会执行类中的setProperties方法进行初始化,代码片段如下:
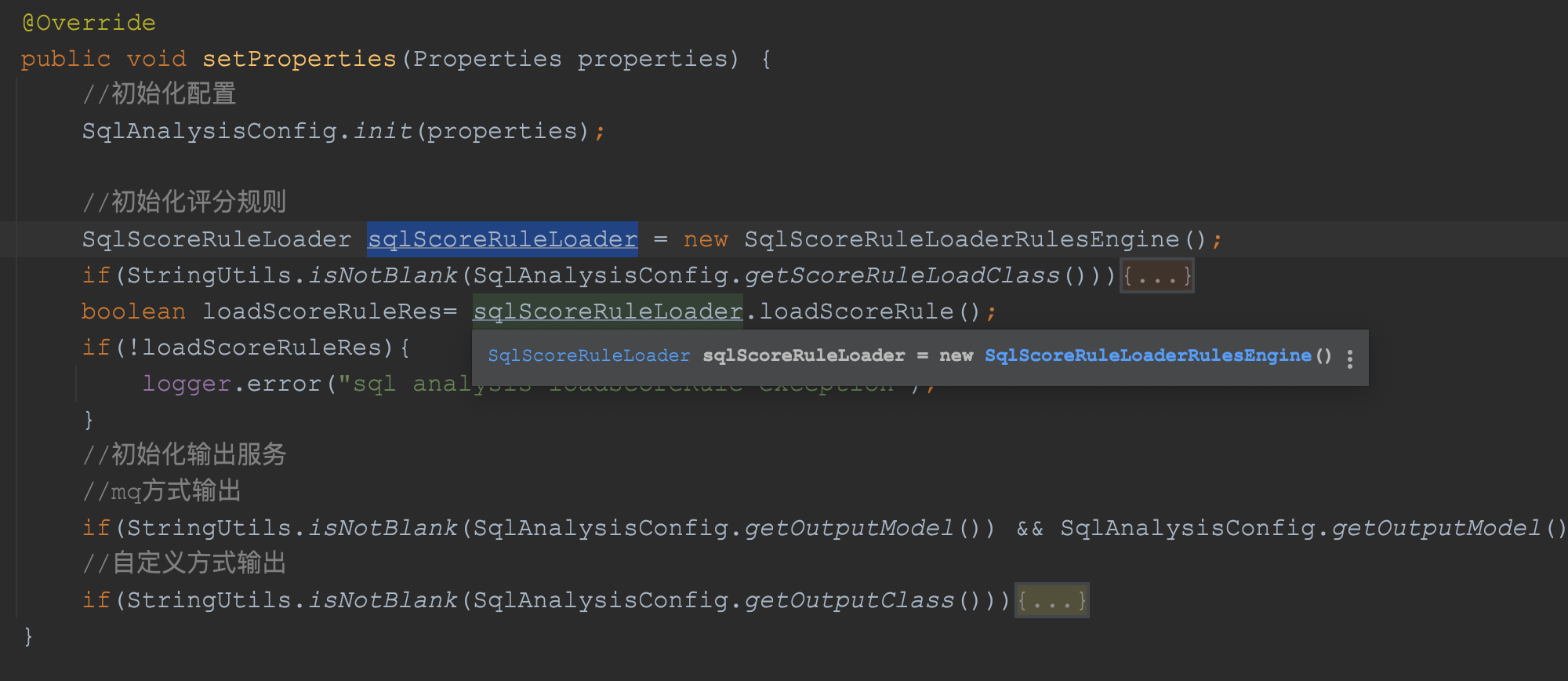
在这个方法中,我们知道了当前拦截器初始化的时候,首先会根据配置信息初始化组件的核心配置,然后初始化规则加载器初始化规则,最后判断是否指定了输出的方式和是否指定了自定义的输出。
然后再intercept方法中,判断当前组件是否开启了,以及第一个参数是否是Prepare的阶段的Connection对象,如果是则执行代码片段:
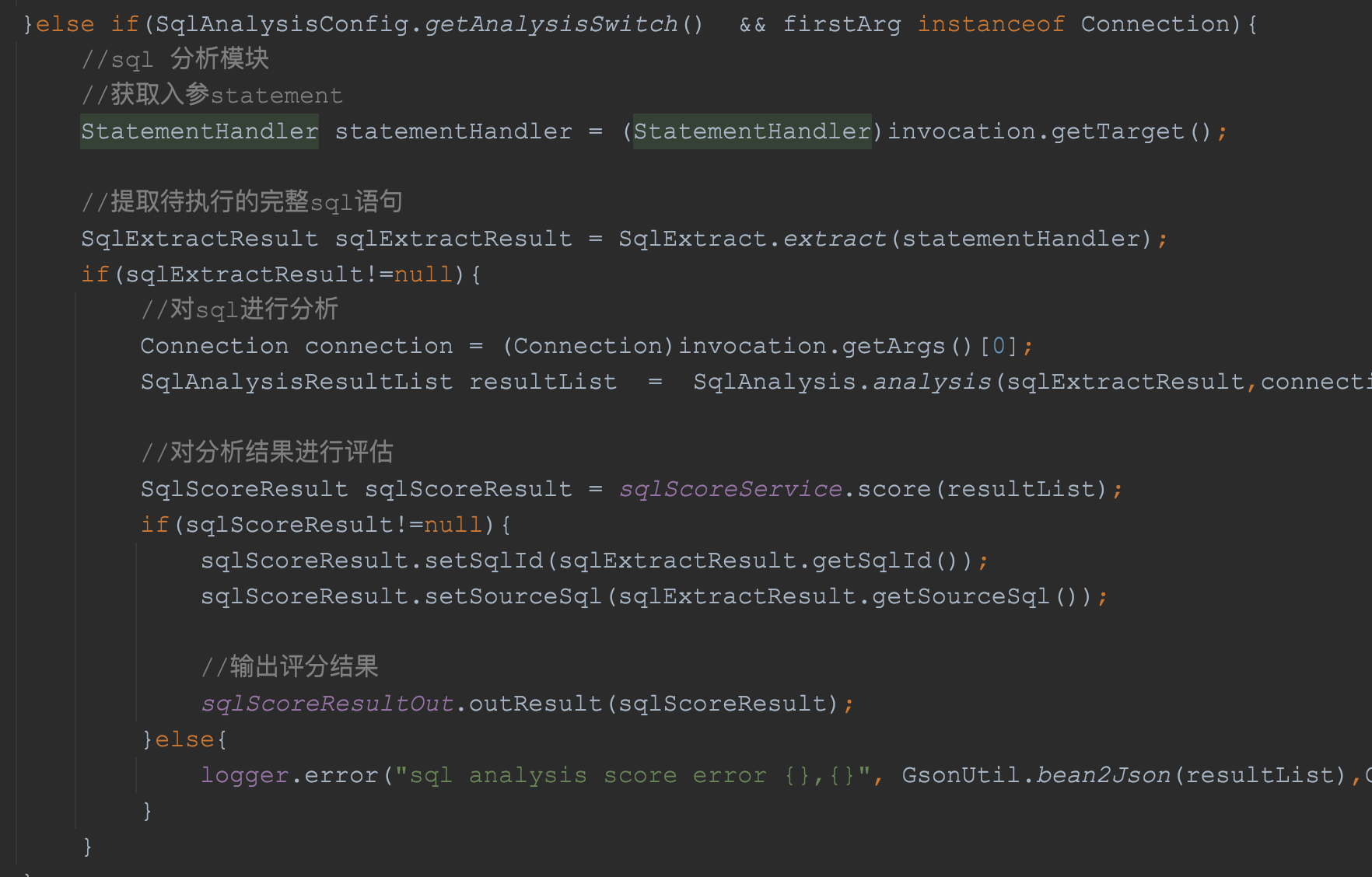
从上面的这个代码片段可以看出来,当前SQL分析组件开启的时候:
这样一看,有没有感觉这个SQL组件很简单呢,好像确实很简单呢,主流程瞬间清楚嘞:
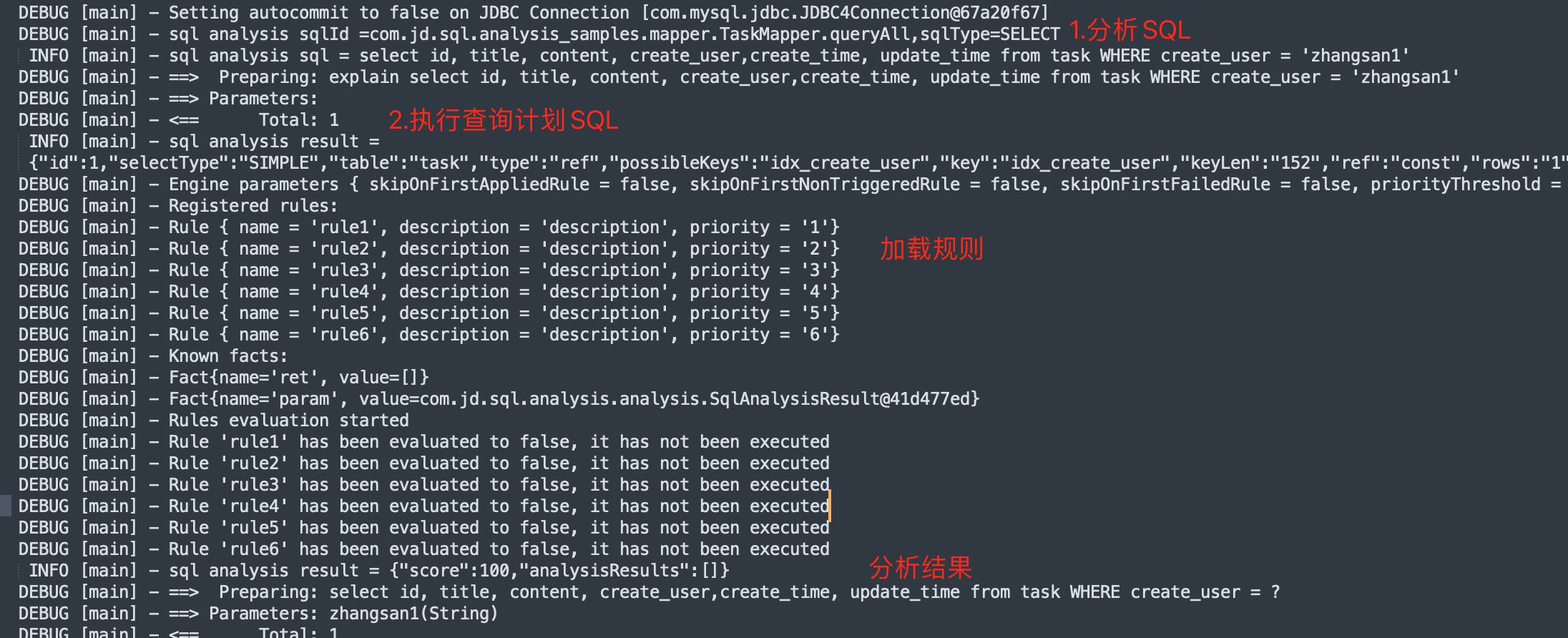
 在我们上一节运行出那个Demo结果的时候,其实通过日志已经非常明显的能够看到一个执行的流程了,如下:
在我们上一节运行出那个Demo结果的时候,其实通过日志已经非常明显的能够看到一个执行的流程了,如下:
2.3、sql-analysis的抽取
当我们了解完这个组件的拦截整个交互流程后,我们开始看看它是如何抽取的,也就是这段代码是如何执行的:
这个类是extract模块的核心设计实现。我们先自己猜一下他的实现过程:
我们通过源码可以看到这个类的代码也很少,不超过207行,熟悉mybatis源码的小伙伴知道,如果想获取mybatis中的配置SQL,首先就是要想办法获取到MappedStatement对象,在抽取模块的extract方法中,如下代码先通过各种判断获得了该对象:
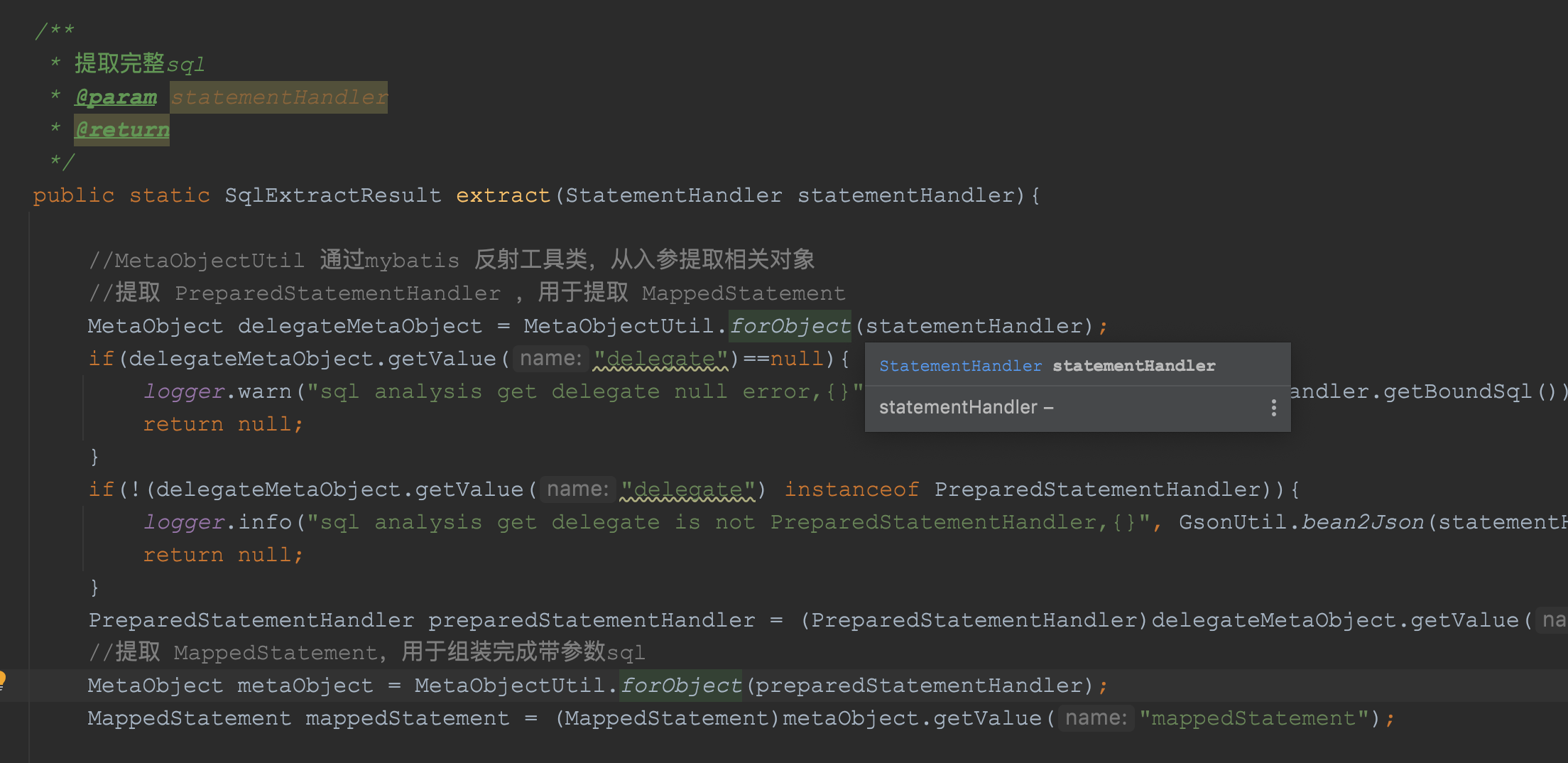
获取到了该对象后,我们就可以获取到SQL等信息了,如下代码:
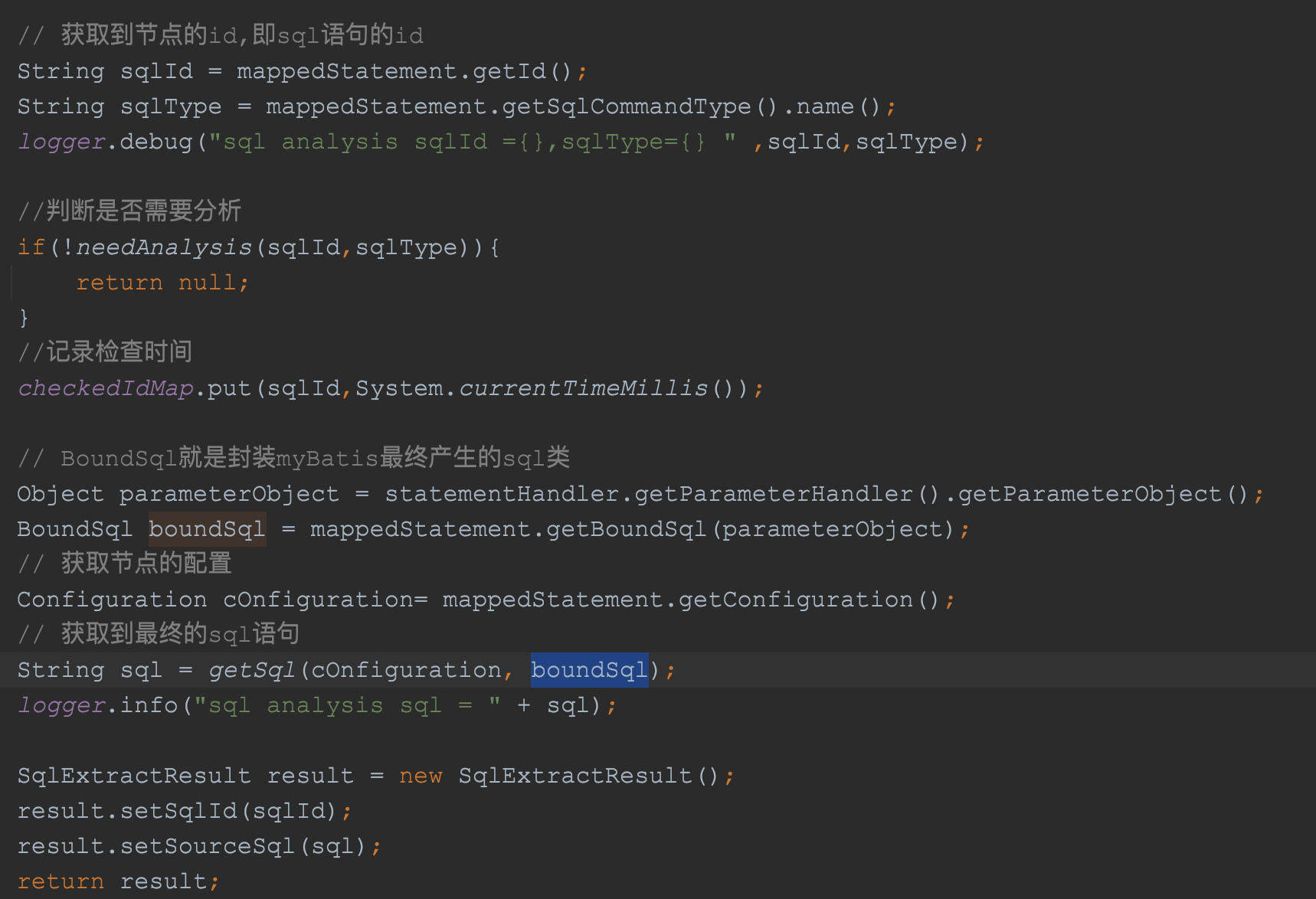
可以非常清晰的看到,该组件的注释是非常不错的,也非常清晰,这段代码的流程更清晰明了:
在是否需要分析方法中,当前提供了4种分析的分支判断:
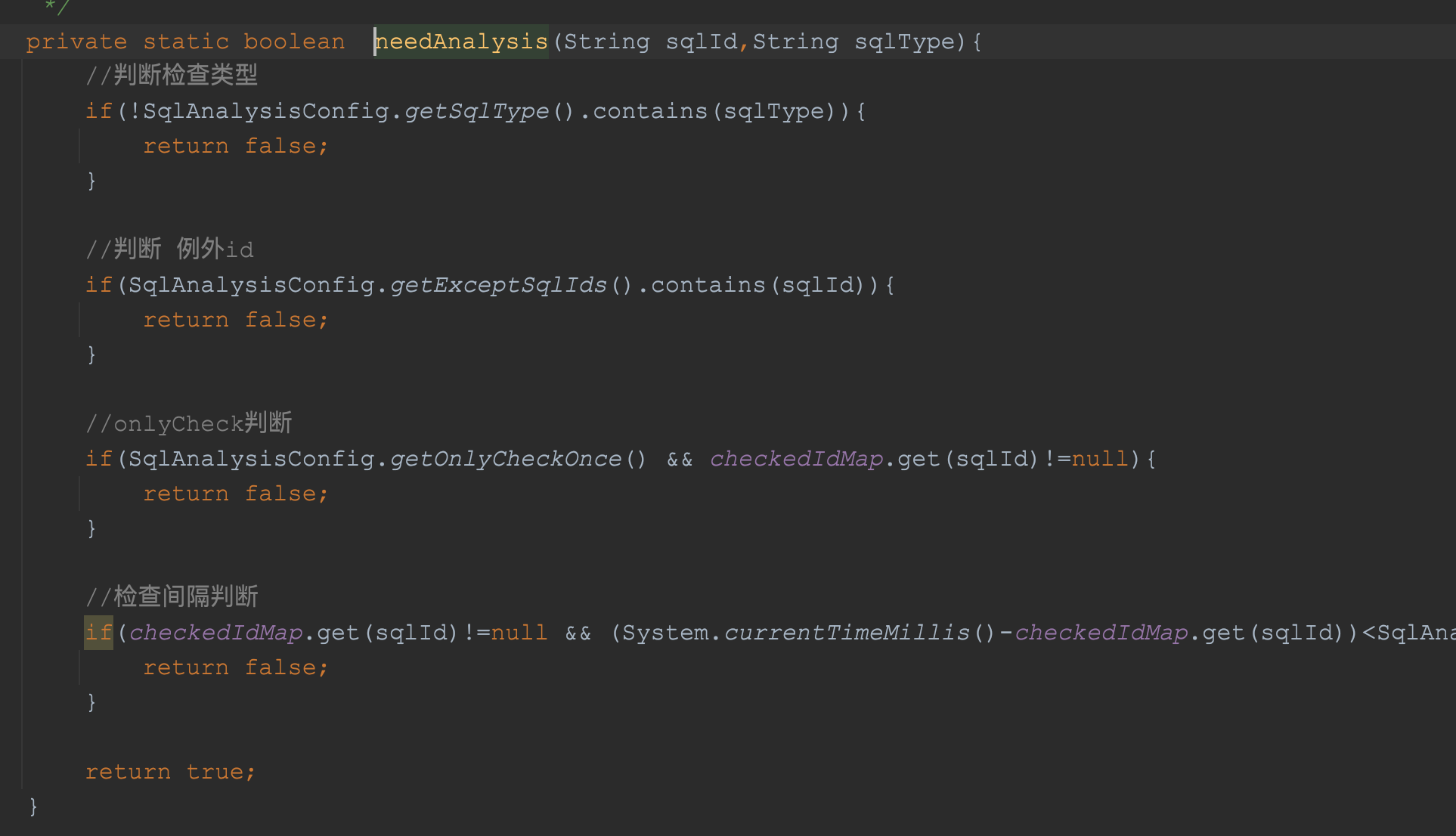
即:
接下来,我们再看下最有价值和可学习的其实是该类中的showSql方法,即将mybatis配置文件中的SQL转换为真实可以执行的SQL,只有这样才能在后续的explain中执行,代码如下:
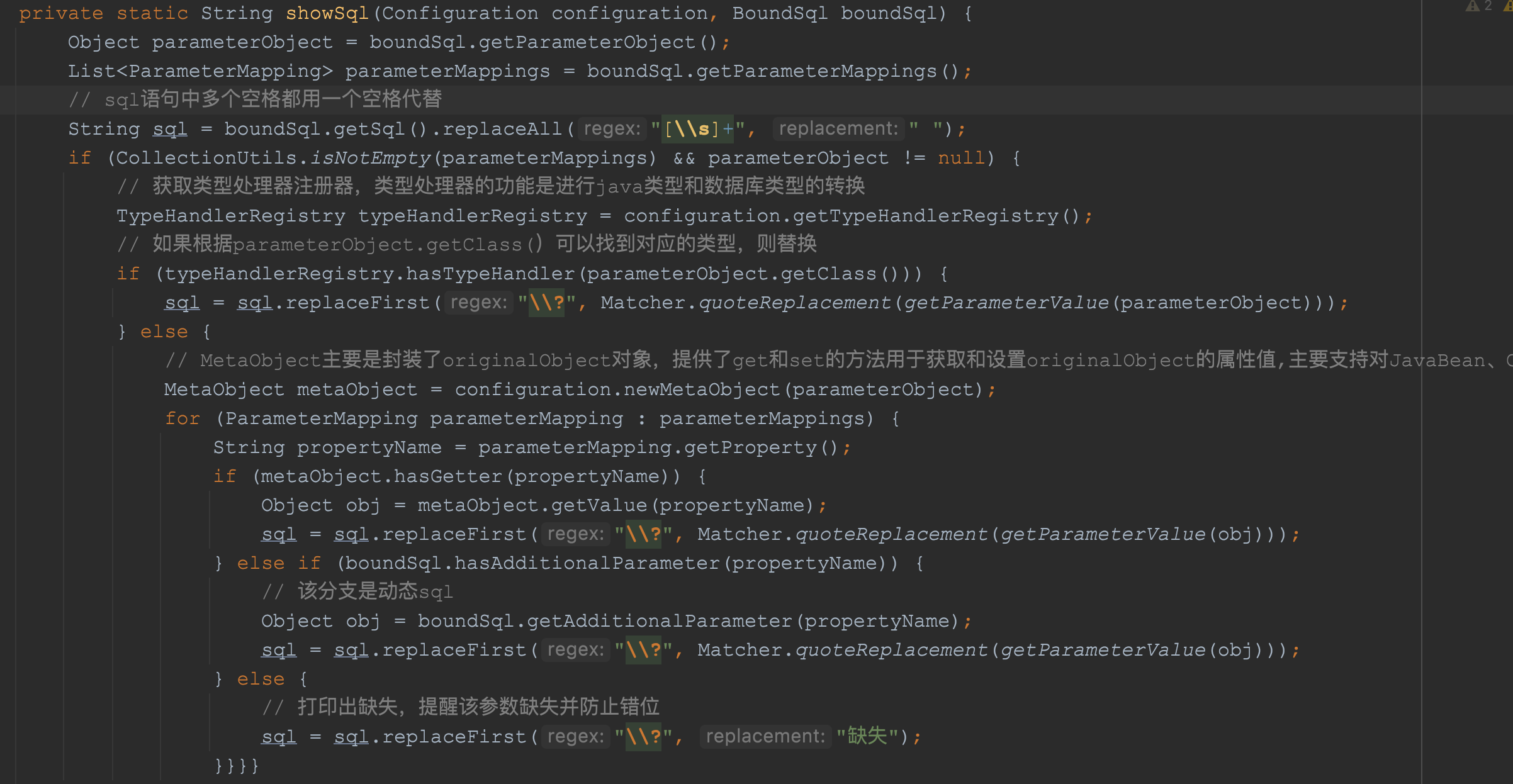
这段逻辑也非常清楚吧,这里我就不多说了,如果日后大家的公司也需要将一个配置级别的SQL转换为真实的执行的SQL的能力的操作的话,我们可以服用这段代码,从而完成真实SQL的生成。
2.4、sql-analysis的查询计划分析
当我们获取到了一个SQL的语句的抽取结果后,就来到了这个组件中的analysis的分析模块,分析模块的入口代码如下所示:
可以看到该方法将SQL语句信息和数据库链接对象传递到了分析模块,我猜它的底层应该是执行了一个JDBC查询操作。我们来确认下是不是。分析模块的代码截图如下所示:
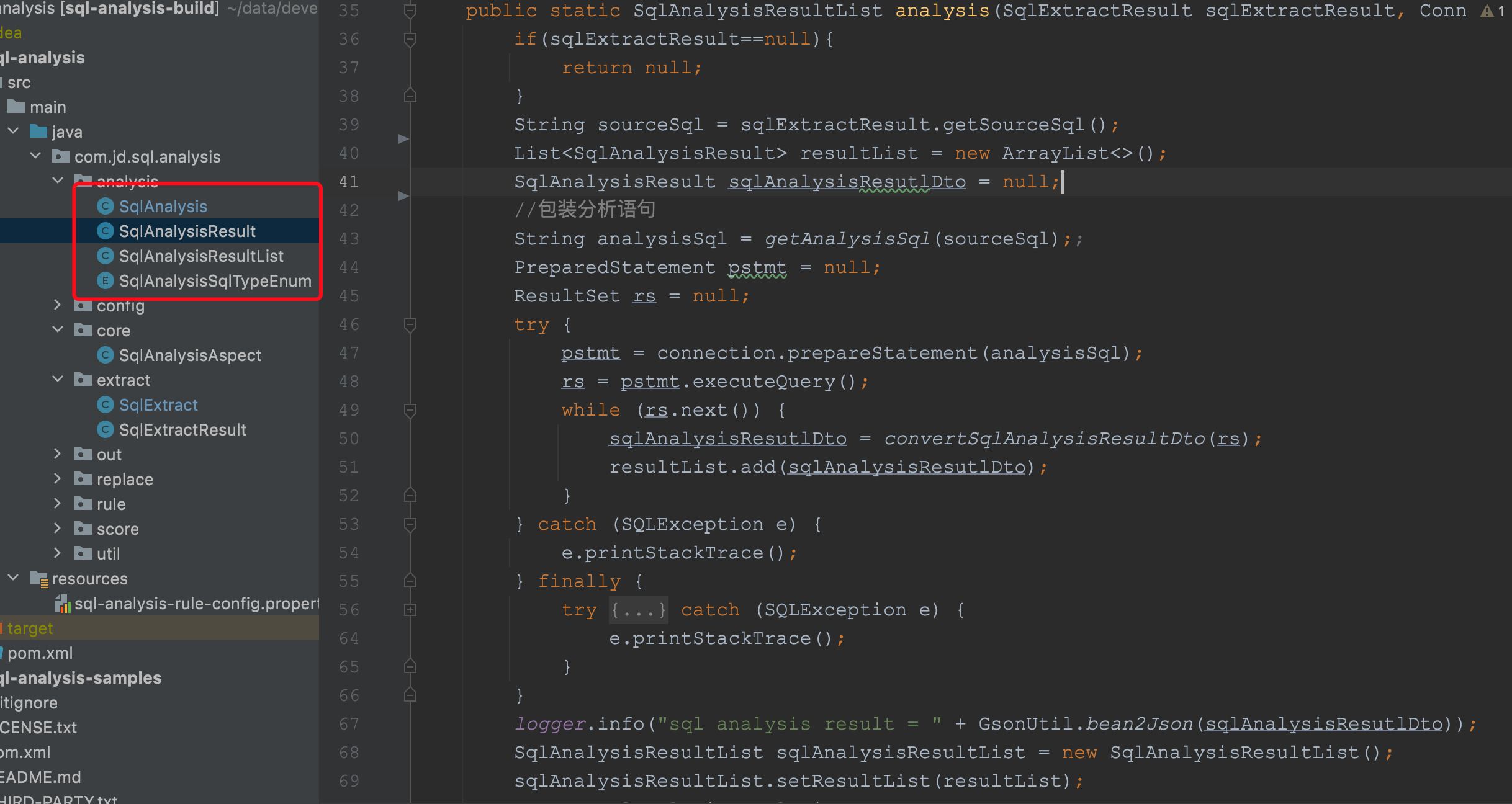
从源码中,我们可以非常清晰的看到这就是一个非常典型的JDBC查询,同时将查询的结果转换为了SqlAnalysisResult对象,该对象的结构本质就是我们数据库中那个explain的执行查询计划的返回结果,字段截图如下:
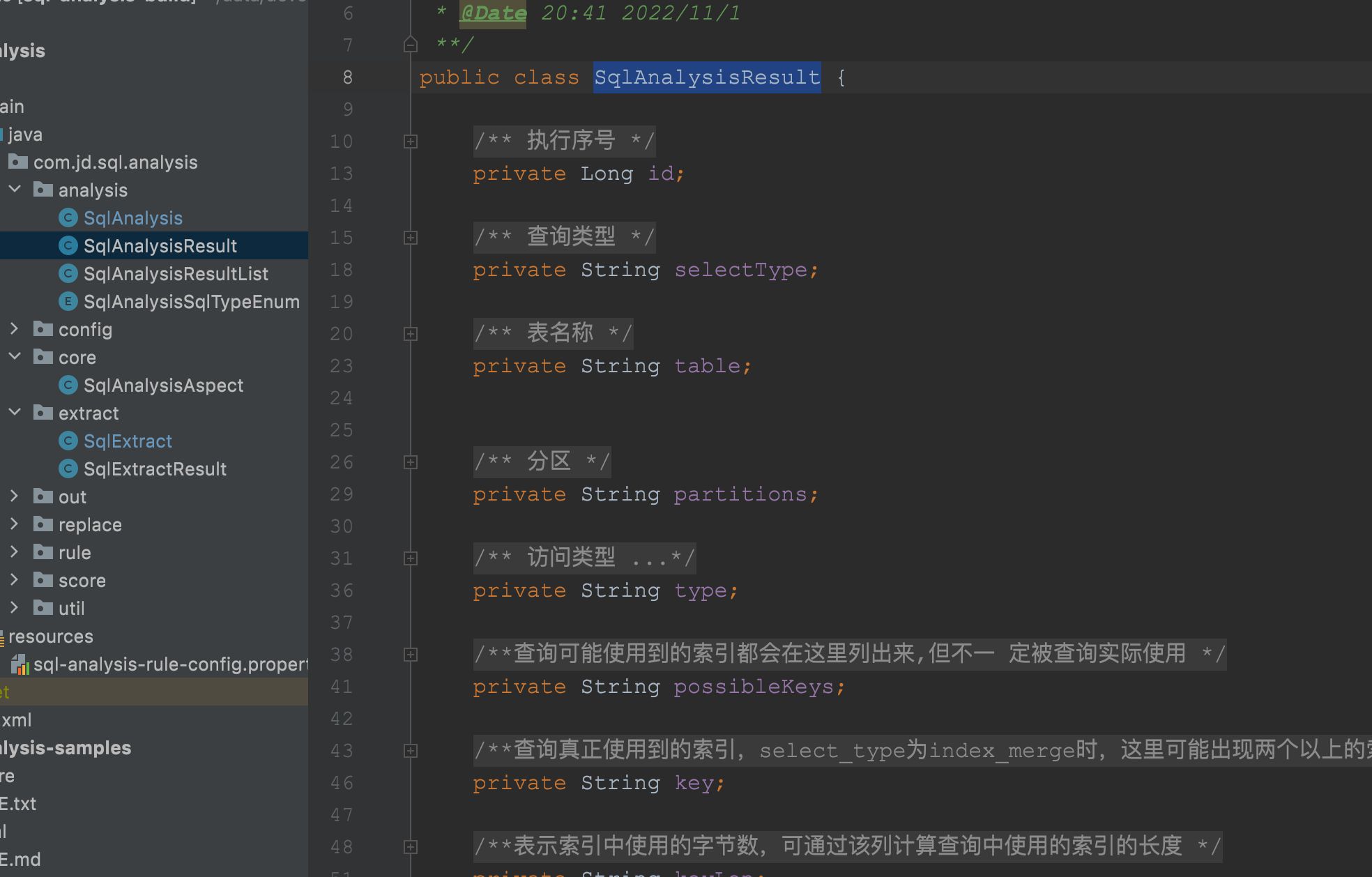
分析模块太简单了吧,确实很简单,就是一个JDBC的查询,在这个模块中,我们需要关注的是这个方法:convertSqlAnalysisResultDto,该方法中将我们的JDBC结果集中的RS对象中的数据转换了最终结果,自己可以去看看,在该方法中,判断了相关的mysql的版本等内容。
这个模块,我们未来如何扩展呢,其实可以可以写一个数据库方言的SPI设计与实现,这样就可以做到多数据库的查询计划的分析结果了。
2.5、sql-analysis的规则打分
当我们有了当前SQL的查询计划执行结果后,我们就到了这个组件最核心的功能:如何判断当前SQL是不符合我们规则的SQL,当前慢SQL的定义是怎么处理的。
在sql-analysis组件中,使用了开源的规则引擎easy-rules进行了规则定义与实现,我们可以在配置文件中动态指定判断条件和规则,如下所示:
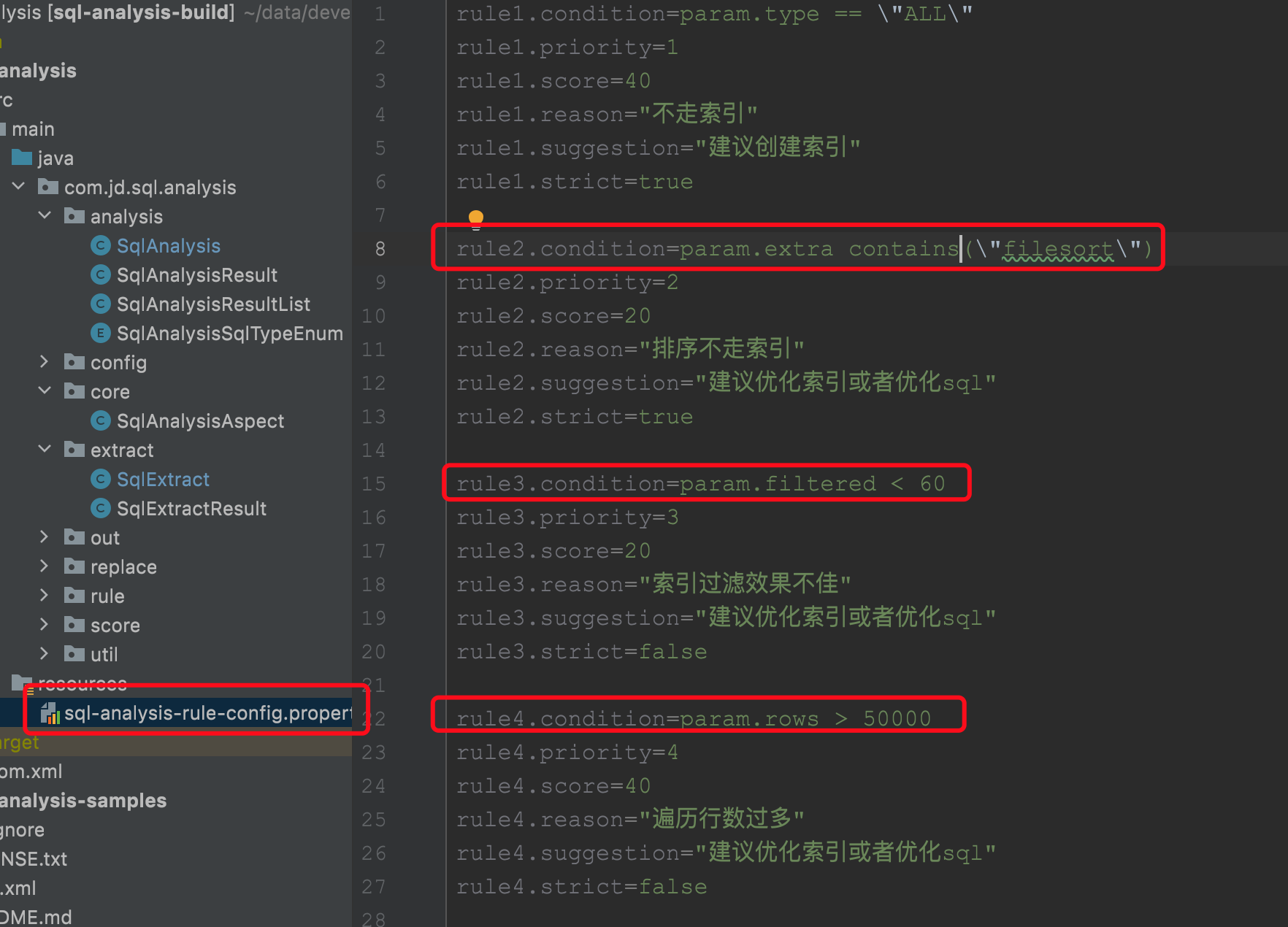
在最开始的流程中,我们看到在拦截器中,也就是项目启动的时候,会执行规则配置的数据的加载,最终会执行到RuleEngineExcutor类中的refresh方法中:
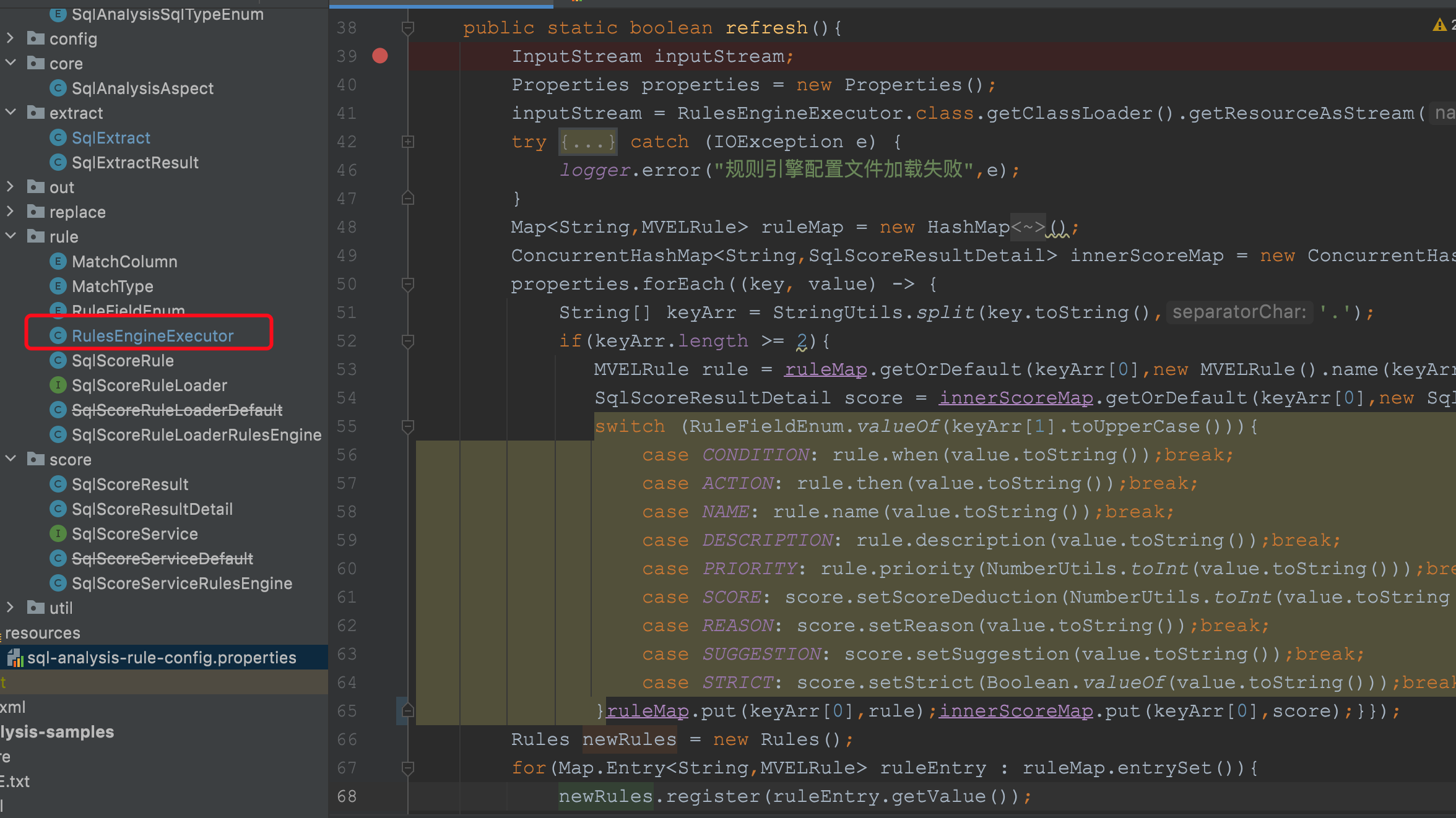
关于规则引擎的介绍,本文不过多说明,我们后续再继续说。
我们再看看这个核心的方法是怎么把一个SQL执行计划的结果,通过规则引擎进行打分的处理的:
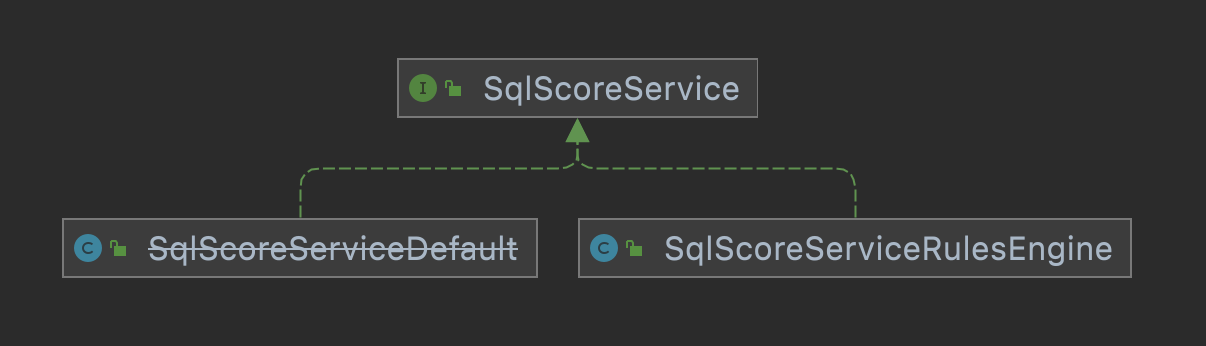
通过类结构可以看到这是一个典型的策略设计模式的应用,给我们提供了一个默认的打分规则和一个基于规则引擎的打分规则,当前使用的SqlScoreServiceRulesEngine类。这个类代码如下:
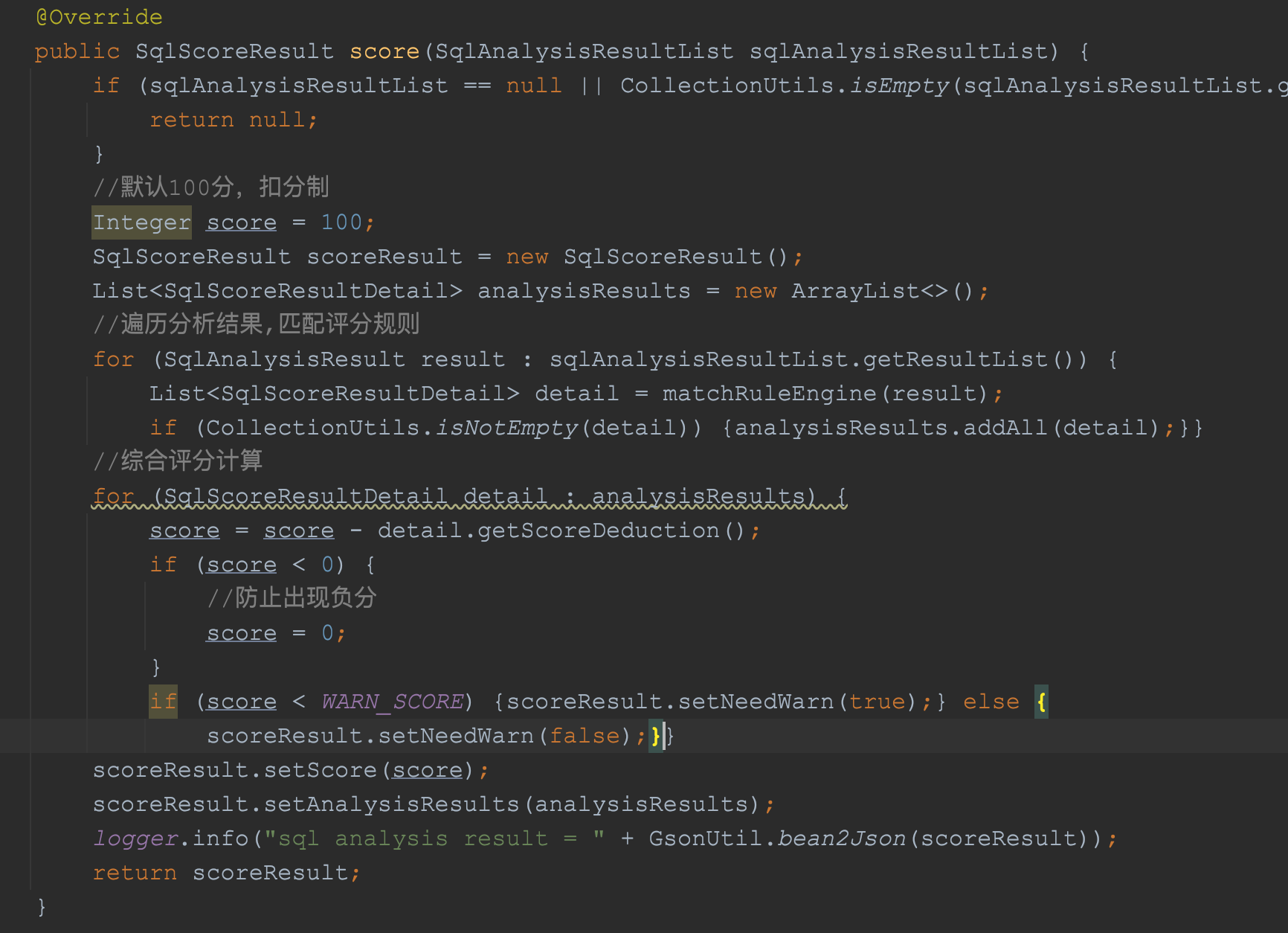
这个类的代码也是很简单,可以看到它会遍历我们的分析结果,然后基于100分,通过规则计算筛选出匹配的规则,然后进行分数扣减,然后将分数和规则执行的结果封装为SqlScoreResultDetail对象返回给使用端。
2.6、sql-analysis的结果通知
当我们获取到SQL分析的结果后,我们需要将结果进行输出,当前输出模块的调用代码如下:
同时,这个组件目前提供了3种方式的输出:
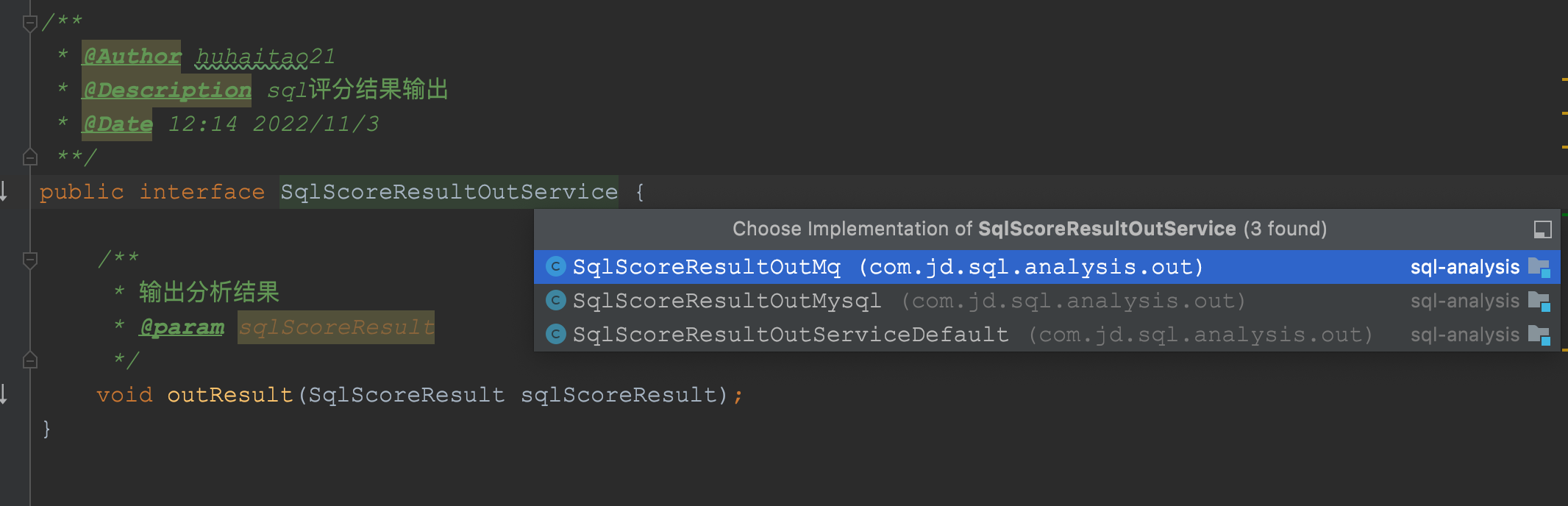
这个设计又是一个典型的策略模式的设计,未来也可以通过SPI插件化的方式,进行业务扩展。
好了,执行到这里我们的源码分析就结束了,是不是感觉这个源码设计的非常简单呢,非常棒呢。我觉得这个源码的设计思路,非常适合在面试中体现。面试的时候,数据库的慢SQL是一个高频问题,如果除了常见的回答外,我们能够把这个组件的核心流程和设计思想作为自己公司解决问题的一部分,同时是自己业务性的创新设计,个人觉得也是一个非常不错的加分项。
三、总结
让我们再来回顾一下这个组件的几个模块的作用和流程吧:
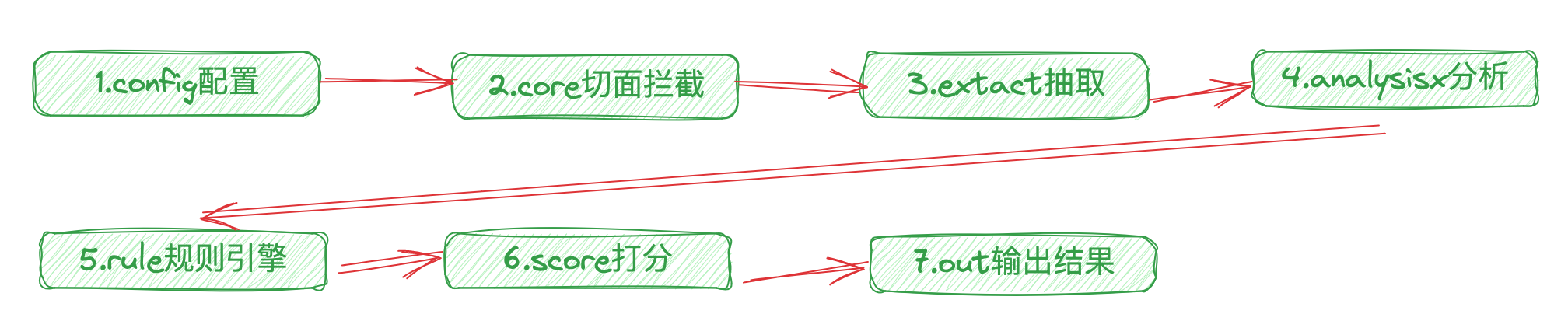
请大家牢记这张图,这是一个慢SQL组件预防的设计思路,希望通过本文这个流程的分析,让大家了解该组件的设计思路与策略设计模式的使用,以及未来的一些基本的扩展方向。